§ Posté le 03/12/2013 à 1h 52m 38
Comme le sous-titre l'indique, ceci est un brouillon, et non pas une véritable conférence que j'aurais déjà effectuée. Je voulais en enregistrer une version audio, mais l'enregistrement n'a pas fonctionné, et j'ai un peu la flemme de recommencer (surtout que j'ai parlé plus longtemps que ce que je pensais avant de me rendre compte du plantage), donc désolé, vous n'aurez qu'une version textuelle pour le moment.
Il s'agit d'un diaporama sur l'auto-hébergement qui tente d'être aussi exhaustif que possible en dix diapositives. Cela peut servir comme support pour des conférences d'une vingtaine de minutes à facilement deux heures, selon le degré d'exhaustivité voulu. Je m'en servirai personnellement si j'ai des conférences à faire et pas beaucoup de temps pour préparer (donc si vous avez lu cet article avant de venir me regarder parler, signalez-vous), mais n'hésitez pas à vous en servir de votre côté si ça peut vous être utile (ni à me signaler d'éventuelles remarques pré- ou post-utilisation).
Cet “article” est typiquement plus adressé à ceux qui vont faire ces conférences qu'à ceux qui vont y assister, désolé par avance.
Le diaporama se trouve ici, et vous trouverez mes sources LaTeX là.
Quelques notes pour accompagner ça, à défaut d'un support audio (si les images sont trop petites, vous pourrez voir en plus grand en téléchargeant le PDF) :

Titre, annonce plan, et objectif : démontrer que l'auto-hébergement est essentiel au bon fonctionnement d'Internet, et que c'est à la portée de toute personne motivée. Je précise que je suis militant du logiciel libre, car, comme le souligne Benjamin Bayart, Internet et les logiciels Libres sont les deux faces d'une même pièce. J'évoque aussi la neutralité du net, qui est indispensable. Enfin, je précise que je suis ancien prof. d'école, pour contrer le mythe selon lequel il faudrait avoir un doctorat en informatique pour savoir faire tout ça : il se trouve que je suis effectivement, maintenant, en train d'en préparer un ; mais à l'époque où j'ai commencé, je savais à peu près coder, mais mes connaissances sur les points que j'aborde dans la conférence étaient à peu près du même niveau que celles de la moyenne des gens sur cette planète.
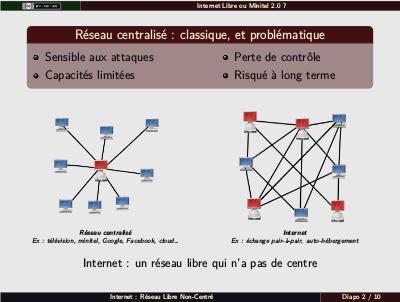
Différence conceptuelle entre le réseau centralisé (intelligence au centre et terminaux stupides) à l'ancienne (quasi-incontournable jusque dans les années 1980) et Internet (intelligence en périphérie, réseau et intermédiaires bêtes). On peut noter au passage qu'Internet n'est pas « un projet militaire », comme on le dit parfois : les militaires ont mit des sous sur la table pour avoir un réseau indestructible ; mais ceux qui ont conçu le truc, ce sont des hippies universitaires dont l'objectif était de faire un réseau incontrôlable (incontrôlable et indestructible allant de paire). Rappel également du fait qu'Internet, quoique distribué, n'empêche pas le fonctionnement centralisé (mais permet de l'éviter). Si Google et Facebook ont une infrastructure qui leur permet de ne pas trop craindre la surcharge, ils restent sensibles aux autres points (pour les attaques, typiquement, PRISM, qui aurait été beaucoup plus dur à mettre en place si tout le monde s'auto-hébergeait).
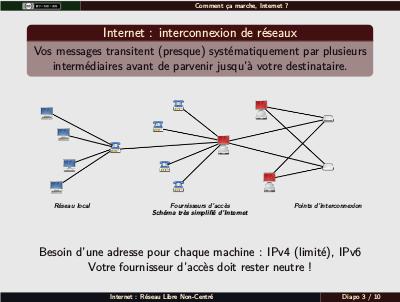
Peut être la plus grosse des 10. Expliquer ici le principe de réseau local (IPv4, une seule adresse IP publique pour la box qui contient un modem et fait office de routeur → donc à configurer pour que le serveur réponde depuis l'extérieur) et de GIX (point d'interconnexion : l'endroit où les différents réseaux des différents FAI communiquent entre eux. Dire un mot sur le fait que les FAI ne peuvent pas aller lire tout le détail des messages, mais voient au moins avec qui on communique, puisqu'ils servent de relai (d'où l'intérêt de la neutralité, ne pas hésiter à évoquer le cas de Free qui bride certains domaines, même si c'est un peu hors-sujet ici). Mentionner le fait que les IPv4 sont en nombre limité et que le passage à l'IPv6 commence à devenir nécessaire. Expliquer à ce niveau le principe des adresses IP, protocoles et ports (deux analogies possibles : rail (→ cuivre, fibre), roues et support du train (→ IP) et aménagement intérieur (sièges, couchettes, marchandises → différents protocoles) ; et interphone (on tape un numéro d'appartement → port ; soit quelqu'un est là et répond, auquel cas il faut causer la même langue que lui pour qu'il ouvre, soit il n'y a personne et la porte reste fermée)).
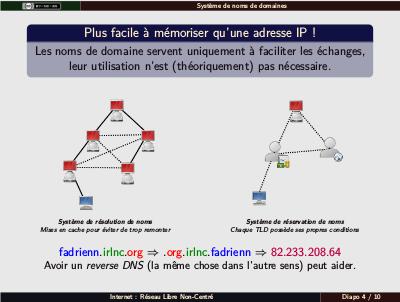
Les noms de domaines ne sont théoriquement pas nécessaires, mais retenir plein d'IP (surtout les v6, encore pire que les v4) est assez délicat. Schéma de gauche : une requête peut remonter, de proche en proche, jusqu'aux serveurs de noms primaires, qui connaissent les serveurs gérant les différents TLD, qui eux-mêmes connaissent les niveaux du dessous. Des mises en cache permettent ensuite d'éviter un second passage. Schéma de droite : l'ICANN fixe les règles générales, et délègue les règles spécifiques à chaque TLD à d'autres entités (l'AFNIC pour le .fr). Les registraires, en application de ces différentes règles, permettent aux administrateurs de sites de réserver leur nom de domaine (pour un an renouvelable). Mentionner éventuellement les symboliques fortes (.edu, vraiment réservé aux grandes universités) et moins fortes (.com, à la base commercial, utilisé pour tout ; domaines par pays utilisés pour la sonorité). La ligne en dessous explicite les trois niveaux de noms de domaines. Le reverse DNS est géré par le FAI, il est utilisé notamment par les antispams. Note : on a le choix ici d'utiliser les DNS de son registraire ou de mettre en place les siens. Un peu de conf' dans les deux cas.

Conditions. Ne pas hésiter à recycler des vieux ordis (typiquement, un portable dont l'écran et/ou le clavier est cassé ne peut plus trop servir comme portable, mais est très intéressant pour faire serveur). Les 10-15€/an sont les frais pour un nom de domaine ; mentionner que certains (dont moi) fournissent gratuitement des domaines de troisième niveau en cas de besoin (et en gérant la configuration DNS pour aller avec). Concernant les FAI, blagues habituelles (Numéricable ne définit pas « serveur », donc interdit aussi de faire venir chez soi un ami travaillant dans un bar ; Internet « par Orange » n'est pas le vrai). Pour mémoire : Bouygues fournit une IP presque-fixe (renvoyer aux diapos d'avant pour expliquer le changement d'IP et l'intérêt de garder toujours la même) ; Orange fournit une IP pas fixe du tout et bloque le port 25 utilisé pour les mails).

Le Web. Donner éventuellement à l'oral le nom de la commande Python (python -m SimpleHTTPServer) en renvoyant vers mon site pour éviter que les gens perdent du temps à noter. Préciser que dans ce cas, ça utilisera le port 8000 plutôt que le 80. Serveur permanent : séparer la partie serveur de la partie applicative. Adapté au centralisé : exemple des ChromeBook (Si OS = navigateur, alors ordi = minitel). Mais plein d'outils pouvant être pratiques, mentionner le cas des réseaux bridés ne laissant passer que le Web (préciser aussi que pour le site/blog aussi, il existe nntp et gopher qui peuvent marcher aussi, même s'ils sont moins pratiques car moins connus du public). Avoir des outils Web n'empêche pas d'avoir d'autres protocoles plus adaptés pour faire la même chose, et réciproquement.
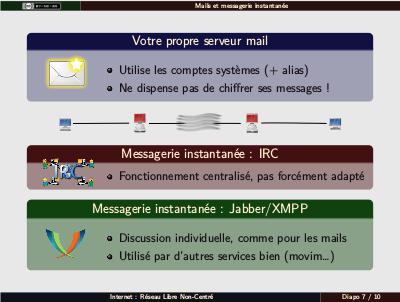
Messageries. Pour le mail : mon login at ma machine, comme les gens normaux
(Benjamin Bayart). Préciser qu'il faut utiliser des mots de passe un minimum solides, surtout avec des logins classiques (« alice/alice » → spam). Mais c'est la condition la plus importante. Rappeler le fonctionnement (et l'échange en clair entre serveurs). Serveur hors-ligne : 24/48h, c'est OK ; quatre-cinq jours, perte de mails ; plus d'une semaine, tout perdu. Possibilité de s'organiser avec d'autres auto-hébergés pour faire relai. En cas d'IP réattribuée anciennement spammeuse, il faut souvent aller demander déblacklistage (mais on y survit). Si beaucoup de temps, rappeler qu'un mail arrive de façon asynchrone (exemple des mails de l'INSA pour prévenir de la fermeture du restau : partent à 9h, arrivent à 15h). Principe d'IRC (qui est le protocole historique) : les gens rejoignent un chan/salon sur un serveur, donc pas extra pour l'auto-hébergement. XMPP : revenir au schéma précédent. Même principe pour l'adresse (mais pas comptes systèmes, donc les deux peuvent être différentes). Présenter un poil movim, réseau social décentralisé utilisant XMPP (X pour eXtensible). Note : si pas possible de faire tourner un serveur en permanence, Jabber marche très bien si le serveur est installé sur la machine de tous les jours et allumé seulement en cas de besoin.
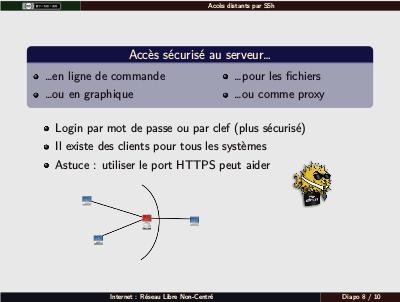
Différentes utilisations de SSh : graphique avec -X, proxy avec -D numéro (permet de relayer pour contourner les blocages, puisque c'est le serveur qui contacte les sites distants à notre place). Présenter les principes de logins par mot de passe, clef en clair (pas de mot de passe, plus pratique) et clef chiffrée (le mode plus sécurisé des trois). Clients pour tous les systèmes : PuTTY (qui ne nécessite pas d'installation) sous Windows (pas pour le X, mais peut-être Cygwin ?) ; natif sous tous les autre systèmes pour PC (y compris Mac OS) ; au moins installable sur les OS pour ordiphones) (Pour les fichiers : fuse/sshfs sous GNU/Linux, sinon scp sous tous systèmes à vrais terminaux. WinSCP sous Windows). On peut utiliser le port 443 plutôt que le port 22 : c'est du chiffré, donc personne ne se rend compte de rien, et le HTTPS n'est généralement pas filtré, donc ça contourne beaucoup de blocages (Quand SSh passe, tout passe
). Le schéma représente le fait qu'on peut utiliser le serveur comme relai pour contacter, par SSh, les machines du réseau local depuis l'extérieur (si elles ont elles aussi un serveur SSh installé).

En fonction du temps dispo qui reste. Sauvegarde : de la machine de tous les jours vers le serveur, mais aussi réciproquement, pratique en cas de disque dur qui lâche d'un côté ou de l'autre. Outils de gestion de version décentralisés très pratiques, qu'on bosse de façon collaborative ou pas. Serveurs de jeux, classique, si les serveurs officiels rament. Pas mal de jeux libres et aussi quelques jeux non-libres sont compatibles. Calcul scientifique : en fonction (automatiquement) de la puissance de calcul dispo. On choisit les projets sur lesquels on veut travailler (beaucoup en astronomie, climat et médecine/biologie). Partage de fichiers : je parle du pair-à-pair, mais d'autres modes sont possibles. Pour le P2P, présenter rapidement le mode de fonctionnement (chacun récupère et diffuse ce qu'il a déjà), et l'exemple classique des serveurs DDL qui rament à la sortie d'une nouvelle version d'Ubuntu (ou autres), alors que les réseaux P2P sont d'autant plus efficaces à ces moments. Préciser éventuellement que 70% de l'échange illégal a lieu hors Internet, et à coup sûr que ces réseaux permettent aussi beaucoup d'échanges légaux (il faut justement occuper le terrain pour montrer ça). Préciser ici qu'un antivirus peut être utile (pas pour nous, mais pour les gens qui récupéreront les fichiers).
Et voilà la conclusion. Rappel des objectifs, en espérant qu'ils aient été atteints. Se lancer dans l'auto-hébergement prend du temps (pas mal de docs à lire, de la conf' à faire sur ses machines), mais c'est globalement à la portée de la plupart des gens pour la partie technique (en tout cas, tant que ça reste un serveur perso sans trop d'usages particuliers). Une fois tous les services en place, l'administration n'est plus particulièrement chronophage (mises à jour régulièrement, lecture rapide des logs de temps à autres, pour l'essentiel, ça suffit). Très facile de trouver des tutos, et une forte communauté prête à aider → renvoyer vers IRLNC et vers mon blog comme porte d'entrée possible.