§ Posté le 27/01/2013 à 1h 07m 12
Note : pas de version audio de cet article, du moins tant que je n'aurais pas eu davantage de retours à ce sujet sur la page dédiée à les recueillir 
Autre note : pour réaliser cet article, j'ai interrogé quelques camarades plus spécialisés que moi dans ce domaine, et je me suis ensuite appuyé sur leurs réponses pour la rédaction. Ne soyez donc pas surpris de voir de nombreuses références à leurs pseudos dans ce qui suit.
Quand j'étais au lycée, à l'époque où nous étions confrontés au grand choix d'orientation entre le bac littéraire et le bac scientifique (mes excuses pour ceux qui ont choisi une troisième option, mais c'était surtout de celles-là que nous parlions), j'ai entendu un certain nombre de fois répéter que les gens scientifiques avaient plus souvent tendance à être bons dans les matières littéraires, que les littéraires à être bons dans les matières scientifiques.
Cette sentence ne m'a jamais vraiment satisfait, surtout que j'avais quelques contre-exemples sous les yeux (même si, bien sûr, un échantillon personnel n'est pas représentatif pour contredire une statistique générale). Ce que je dirais, moi, pour expliquer les mêmes constatations de différences de niveaux entre les matières, c'est que les gens qui se trouvaient être bons dans les deux domaines avaient plus tendance à choisir la filière scientifique. Ce qui change pas mal les conclusions.
Dans le même ordre d'idées, j'ai entendu un certain nombre de fois, après une réponse à une image digne d'un test de Rorschach ou à une énigme tarabiscotée, une réponse du genre « tous les psychopathes qui ont répondu à cette question ont répondu comme toi(1) », ce qui est totalement non-pertinent. L'analyse intéressante à ce sujet aurait été de connaître la proportion de psychopathes ayant donné cette réponse, parmi l'ensemble des personnes ayant répondu, psychopathes ou non (mais ça aurait cassé l'effet recherché, j'imagine).
On rencontre également ce problème d'interprétation pour des sujets plus importants. Par exemple, à chaque élection où le taux d'abstention est important, on trouve quelques personnes dans les journaux télévisés pour nous apprendre que « les gens se sont abstenus parce que… ». Quelle que soit la raison invoquée, une phrase qui commence comme ça pose déjà quelques problèmes : comment peut-on prétendre pouvoir donner l'avis de gens qui se sont précisément illustrés pour ne pas avoir donné leur avis ?
Au passage, ce n'est pas le seul problème de ce genre dans le mode d'application actuel du vote. Même un vote exprimé peut d'ailleurs être interprété de diverses manières (choix du meilleur, du moins mauvais, vote supposé « utile »…)(2).
Car le véritable objet de cet article, après une introduction quelque peu variée, est de vous donner quelques clefs (oui, j'aime bien les clefs) pour lire et analyser les courbes et les sondages que l'on nous propose.
La première chose à laquelle il faut être vigilant, c'est bien sûr la manipulation flagrante. Regardez par exemple cette image(3) :
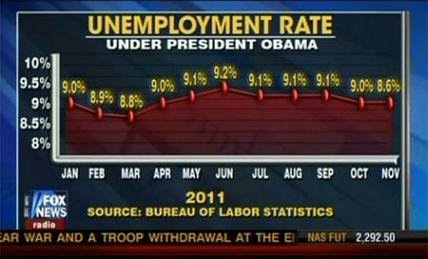
Entre autres points intéressants à noter, voyez la position du dernier point sur l'axe des ordonnées, par rapport à la valeur indiquée : il y a ici clairement un problème précédant toute tentative d'interprétation.
Mais, l'hypothèse d'une telle manipulation écartée, il convient de faire attention à d'autres facteurs.
Commençons par un peu de vocabulaire : l'axe des ordonnées est l'axe vertical (ou « axe des Y ») de la courbe, et l'axe des abscisses en est l'axe horizontal (ou « axe des X »). On dit donc « en abscisse » (ou « en X ») pour situer horizontalement les points, et « en ordonnée » (ou « en Y ») pour les situer verticalement.
Conventionnellement, on présente sur les courbes « l'évolution des Y en fonction des X », c'est-à-dire qu'on trace la courbe de manière à ce qu'elle présente la façon dont l'élément indiqué en ordonnée change quand l'élément indiqué en abscisse change.
Si la courbe évolue « vers le haut », c'est-à-dire que l'ordonnée augmente à mesure que l'abscisse augmente, on dit que la courbe est croissante ; dans le cas contraire (donc, si l'ordonnée diminue à mesure que l'abscisse augmente), on dit que la courbe est décroissante. En maths, on rajoute strictement croissante ou décroissante si, à aucun moment, la courbe ne semble s'arrêter et rester stable. Si elle reste stable d'un bout à l'autre, on dit qu'elle est constante.
Un peu plus de vocabulaire : une courbe peut tout-à-fait changer de direction, et même plusieurs fois, dans l'intervalle qui est présenté. Si elle ne le fait pas, et qu'elle conserve donc toujours la même direction (que ce soit une croissance ou une décroissance), on dit que la courbe est monotone (encore une fois, « strictement monotone » si à aucun moment elle ne devient constante).
C'est tout pour le vocabulaire de matheux ^^
Maintenant, donc, les éléments auxquels il faut faire attention.
D'abord, et en premier lieu, l'effet d'échelle : de mêmes valeurs peuvent sembler très distantes les unes des autres, donnant l'impression d'une courbe à forte variation, ou au contraire très proches, donnant l'impression d'une courbe stable, simplement en « zoomant » ou en « dézoomant ». La différence entre la valeur initiale et la valeur finale des graduations sur chacun des deux axes vous donne une estimation essentielle pour interpréter l'aspect général de la courbe.
Notez d'ailleurs, dans le même ordre d'idée, que le point d'origine des axes n'est pas forcément le point de coordonnées (0, 0). Même à la même échelle, une courbe dont les ordonnées proposées vont, par exemple, de 0 à 1000 semblera forcément plus « basse » qu'une courbe dont les ordonnées proposées vont de 500 à 1500.
Ça paraît évident à dire, comme ça, mais ça ne saute pas forcément aux yeux quand on regarde la courbe.
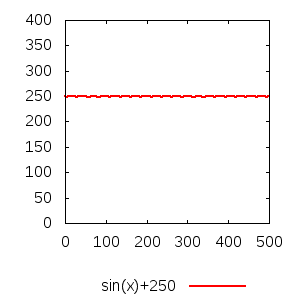
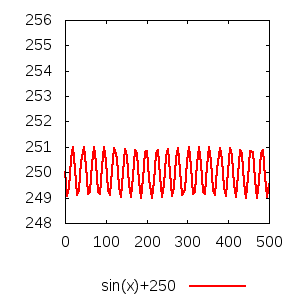
Mais, s'il est important de vérifier où commencent et où finissent les valeurs sur les axes, la façon dont elles évoluent est importante également. La plupart du temps, on essaye de faire en sorte que l'échelle soit linéaire, c'est-à-dire que l'espace séparant deux traits sur l'axe soit proportionnel à la différence entre les deux nombres correspondant ; mais ce n'est pas toujours le cas.
Pour montrer davantage certaines évolutions, il peut être intéressant d'employer plutôt une échelle logarithmique, qui affichera, par exemple, une distance égale entre 1 et 10, entre 10 et 100, entre 100 et 1000, et ainsi de suite. En général, si la courbe est faite honnêtement, ce type d'échelle est explicitement précisé, mais même si elle ne l'est pas, vous pouvez le voir sur les graduations.
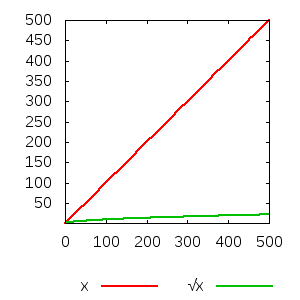
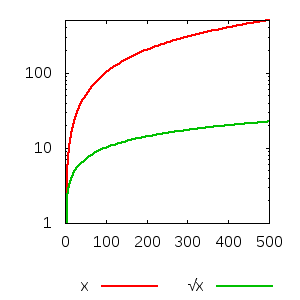
Un autre aspect très important à prendre en compte : la présentation de la courbe comme « la variation de Y en fonction de X » peut laisser entendre que les changements apportés sur X seraient la cause des changements constatés sur Y, ce qui n'est pas forcément le cas.
Prenons un exemple, que vous avez tous pu constater à l'approche de l'hiver : plus les feuilles tombent des arbres, plus la durée des jours se raccourcit. Inversement, au printemps, l'arbre récupère ses feuilles, et la durée des jours augmente. Il est donc tout-à-fait possible de tracer la courbe de la durée du jour en fonction de la quantité de feuilles sur les arbres… ce qui ne veut pour autant pas dire que la chute des feuilles ait une quelconque influence sur la durée du jour.
Autre exemple, que m'a soufflé Héliade : plus il y a de neige sur le sol, plus le nombre d'accidents de ski est important. On peut même aller plus loin et signaler que, lorsqu'il n'y a plus de neige du tout, le nombre d'accidents de ski devient ridiculement faible. Est-ce à dire que la quantité de neige serait directement responsable du nombre ces accidents, et que pour skier en toute sécurité, il faudrait le faire quand il n'y a pas de neige ?
On pourrait en trouver un paquet d'autres(4)(5) dans ces genres : le fait est qu'un rapport entre deux évolutions (on appelle ça une corrélation) ne signifie pas forcément que l'une de ces deux évolutions cause l'autre. Corrélation n'est pas lien de causalité.
D'autant que la taille de l'échantillon concerné peut avoir une influence certaine sur une éventuelle corrélation. Plus l'échantillon envisagé est « petit », moins les valeurs présentées ont de chances d'être représentatives.
Ce que l'on pense être une tendance durable peut n'être en fait qu'un incident dû à l'intervalle étudié. Supposons par exemple que je trace la courbe des ventes de cerises en fonction du temps. Si je mets les semaines écoulées en abscisse et que ma courbe va d'avril à juin, je verrais très probablement se dessiner une courbe franchement croissante ; nous savons pourtant que si je prolongeais cette courbe jusqu'en septembre ou en octobre, j'assisterais alors à une forte baisse.
De tels artefacts se rencontrent souvent dans les données traitant de la diffusion de l'information, où les courbes peuvent présenter une phase d'initialisation, puis évoluer différemment une fois une valeur particulière dépassée.
De la même façon, quand un article de journal annonce en titre que « X pourcent des français répondent telle chose », c'est simplement… faux. En fait d'X% des français, il s'agit d'un pourcentage des personnes interrogées. À l'instant où j'écris ces lignes, nous sommes, je crois, aux alentours de 60 millions : même si un million de personnes avait été interrogé, il en resterait 59 dont on n'aurait pas l'avis.
Ça ne veut bien sûr pas dire qu'il faille jeter le résultat à la poubelle, mais simplement que le résultat proposé ne correspond pas forcément à celui que l'on obtiendrait si l'on interrogeait tous les français – on voit régulièrement des différences pouvant être assez notables entre les sondages et les résultats des votes, par exemple.
La représentativité du panel de personnes sondées est également importante. Si je pioche ce million de personnes à la sortie d'un meeting politique, j'aurai sans doute des résultats moins variés que si j'interroge des personnes au hasard dans la rue.
Tiens, un sondage que j'ai mené moi-même : à la question « aimez-vous mon blog ? », ≃67% des personnes interrogées ont répondu « oui »… et les ≃33% restants ont répondu « mraou ». Bah oui : je n'ai demandé qu'à moi, ma coloc' et son chat.
Oui, bon, je sais, le coup du chat est assez caricatural ; mais même pour des humains, la question de la compréhension du texte est assez importante.
Par exemple(6), quand on pose la question « avez-vous lu au cours des sept derniers jours ? », qu'entend-on exactement par « lire » ? Regarder un tract, feuilleter un magazine, sont techniquement des activités de lecture ; pas sûr cependant qu'un individu travaillant dans la littérature ne pense spontanément à répondre « oui » en pensant à de telles activités.
Plus encore, la simple façon de poser la question peut aiguiller de manière assez importante les résultats. Pour citer un bout de texte récupéré sur l'ancien blog de Marie-Lou (ça vient d'un ouvrage de François de Singly intitulé Le questionnaire) :
La même année, la croyance avouée en Dieu baisse de 15% entre deux sondages : différence qui s’explique par une variation de la formulation des questions. Le « Croyez-vous en Dieu ? » obtient 81% de « oui », et le « Est-ce que vous croyez en Dieu ? » seulement 66%. Le « Est-ce que » diminue l’évidence de la croyance en Dieu, le fait de croire apparaissant moins comme la norme de référence. L’injonction de répondre « oui » est moindre.
S'il y a plusieurs questions, il est important de noter qu'elles peuvent également influer les unes sur les autres. Si la première question demande un avis général, celui qui a commencé par donner un avis positif risquera ensuite d'être moins critique sur les questions portant sur des points précis, ce qui donnerait une impression de contradiction.
Marie-Lou me suggère, à ce sujet, cet article détaillant la façon dont est construit un sondage sur les hypothèses complotistes de l'attentat du World Trade Center, et illustrant par là un certain nombre de biais possibles.
Ça sort un peu du contexte que je souhaitais aborder, mais en fait, l'idée même de faire un sondage sur un sujet donné peut déjà être analysée, comme le souligne Pierre Bourdieu dans cet article qui m'a, encore une fois, été transmis par Marie-Lou(7)
Que dire d'autre ? Le Rouge nous rappelle de faire attention à la façon dont les chiffres sont obtenus et à ce qu'ils représentent. Comparer, en effet, des valeurs obtenues par deux méthodes différentes n'est pas forcément très pertinent.
Je l'ai déjà cité en vitesse dans mon dernier article à propos de la manière de définir l'illétrisme : les critères actuellement utilisés sont beaucoup plus sévères que ceux qui avaient cours au XXe siècle, où, comme le souligne Sylvain Grandserre, l'on pouvait pouvait se contenter d'un déchiffrage oralisé, ânonné, pour donner l'illusion de savoir lire
. À ce sujet, comparer les statistiques de l'époque avec les statistiques actuelles n'a donc pas grand sens (mais on peut obtenir des comparaisons pertinentes en étudiant l'illétrisme, avec les critères actuel, en fonction de la génération, par exemple).
Autre exemple, les chiffres de la délinquance sont parfois « trafiqués » par des comparaisons « entre choux et carottes » pour donner l'impression désirées : par exemple, prendre d'un côté le nombre de vols simples, et de l'autre, le nombre de vols avec violences peut donner une impression d'augmentation ou de diminution qui n'est pas fondée.
D'une manière générale, les chiffres avancés dans les débats politiques sont rarement sourcés, et il convient d'y prêter attention. Témoin, cette analyse du débat ayant eu lieu entre les deux tours de la dernière campagne présidentielle et en relevant les inexactitudes.
Pour conclure, si vous avez vous-même des sondages à faire ou des courbes à présenter, faites attention à ces éléments : il est essentiel de présenter les choses de telle sorte que les informations importantes en ressortent, sans pour autant « forcer le trait ». Et – je suis bien placé pour le savoir, étant précisément en train de rédiger une publication contenant quelques courbes – ce n'est pas toujours trivial.
Mais surtout, et l'auteur d'XKCD ne me contredira pas sur ce point, me semble-t-il (version francophone), un truc est extrêmement important : pensez toujours à étiqueter vos haches axes.
(Je crois, sans en être sûr, que cette dernière image vient à l'origine d'ici)
Petits sourçages pour finir : les courbes dont je n'ai pas indiqué la provenance ci-dessus ont été réalisées par mes soins, à titre d'exemple, et à l'aide du logiciel gnuplot (mon trace.plt). Je remercie une fois encore Héliade, Le Rouge et Marie-Lou, dont j'ai sollicité les avis concernant les points à aborder prioritairement dans cet article, et dont, comme je l'ai dit, les réponses m'ont servi de base dans ma rédaction.
Modifié le 09/02/2013 à 18h 20m 13
Mise à jour :
Marie-Lou a publié sur son blog un très bon article qui assure la continuité de celui-ci. J'invite cordialement mes lecteurs intéressés par le sujet à aller le lire